马克威协同过滤
马克威操作说明
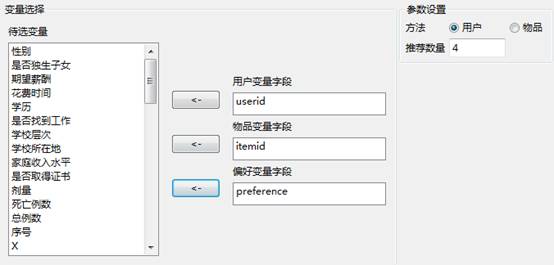
(1)以数据文件“马克威通用数据3.mkw”为例,演示协同过滤算法的操作。首先,在工作区内,打开建模分析工作流:“机器学习”→“协同过滤”,接着选择数据源,然后设置算法的参数,最后点击运行按钮。
其中各类参数的含义为:
用户变量字段:选择用户信息的字段
物品变量字段:选择被评价的物品字段
偏好变量字段:用户对物品的评价信息
参数设置:基于用户的协同过滤算法(user-basedCF),和基于物品的协同过滤算法(item-basedCF)。
参数设置如下所示:
(2)输出结果
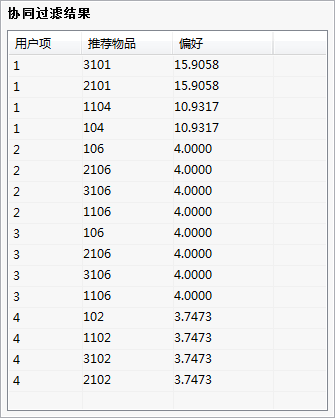
(3)结果说明
示例数据对用户的偏好进行分析,并给出根据用户不同偏好的推荐结果。
数据要求
输入数据类型:数值型、字符型数据
算法用途
协同过滤算法的主要功能是预测和推荐。经常被用来分辨某位特定顾客可能感兴趣的东西,并给他推荐相应的产品,而这些结论主要来自于对其他相似顾客对哪些产品感兴趣的分析。协同过滤以其出色的速度和健壮性,广泛应用于互联网等领域。
算法原理
协同过滤算法的主要功能是预测和推荐。协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-basedCF),和基于物品的协同过滤算法(item-basedCF)。
基于用户的协同过滤算法是通过用户的历史行为数据发现用户对物品喜爱程度,并对这些喜好进行度量打分。通过不同用户对商品态度和偏好程度计算用户之间的关系,对有相同喜好的用户间进行商品推荐。
基于物品的协同过滤算法是通过计算不同用户对不同物品的评分获得物品间的相关关系。基于物品间的相关性对用户进行相似物品的推荐。其中相似性度量标准为:用欧几里德距离和皮尔逊相关系数。
欧几里德距离:
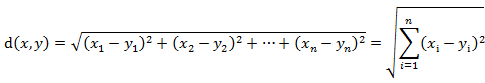
皮尔逊相关度:
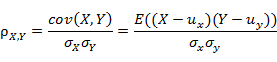
结果与解释
输出结果:给出协同过滤推荐的结果,包括给用户推荐的商品ID以及对推荐商品用户的偏好程度。