马克威孤立点分析
马克威操作说明
以数据文件“马克威通用数据1.mkw”为例,演示孤立点分析算法的操作。数据描述了N维空间(N=8),有100个点,它们在(1,2,…,8)维上的坐标,分别用V1、V2、V3、V4、V5、V6 、V7 、V8 表示,试对它们进行孤立点分析。
首先,在工作区内,打开建模分析工作流:“机器学习”→“孤立点分析”,接着选择数据源,然后设置算法参数,最后双击运行按钮。添加变量到已选变量列表,要求“根据记录分离”3个孤立点,设置好参数如下所示:
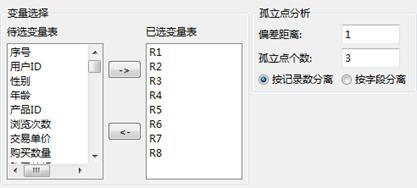 孤立点分析-属性设置
孤立点分析-属性设置
选项说明
偏差距离:要求输入一个整数,对计算的精度有一定的影响,对结果没什么影响,系统默认值为1。
孤立点个数:设置在结果孤立点表中要列出的孤立点个数,系统默认值为1。
按记录分离:本方式是按记录寻找并分离孤立数据集合。
按字段分离:本方式是按字段寻找并分离孤立数据集合。
运行后,结果显示分离出的3个孤立点的信息:
 孤立点分析-树形结果列表
孤立点分析-树形结果列表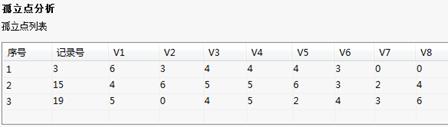 孤立点分析-孤立点列表
孤立点分析-孤立点列表
注:对每一列中出现的缺失值,系统将使用该列的平均值填补,对于整型数据,如果该列平均值为小数,将按四舍五入取整。
数据要求
输入变量类型:整数型。
算法用途
孤立点分析被广泛地应用于各种行业,如电信和信用卡欺骗(如检查购买金额或购买次数异常等)、贷款审批、药物研究(如用于发现对多种治疗方式的不寻常的反应)、气象预报、金融领域(如检查洗钱等异常行为)、客户分类(如确定极低或极高收入的客户的消费行为)、网络入侵检测等。
算法原理
孤立点分析是数据挖掘中一个重要方面,用来发现“小的模式”(相对于聚类而言),即数据集中显著不同于其它数据的对象。
Hawkins(1980)给出孤立点(outlier)的定义:孤立点是在数据集中与众不同的数据,使人怀疑这些数据并非随机孤立点,而是产生于完全不同的机制。孤立点可能在聚集运行或者检测的时候被发现,比如一个人的年龄是999,这在对数据库进行检测的时候就会被发现。还有就是outlier可能是本身就固有的,而不是一个错误,比如CEO的工资就比一般员工的工资高出很多。
 孤立点
孤立点
孤立点的挖掘方法主要有:基于统计学的、基于距离的、基于密度的和基于深度的方法。
马克威孤立点算法是基于距离的:设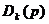 表示点
表示点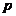 和它的第
和它的第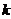 个最近邻居的距离。直观地看,越大,越有可能成为孤立点。给定
个最近邻居的距离。直观地看,越大,越有可能成为孤立点。给定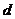 维空间中包含N个点的数据集、参数
维空间中包含N个点的数据集、参数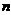 (孤立点个数)和(偏差距离),如果满足
(孤立点个数)和(偏差距离),如果满足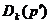 >的点
>的点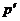 不超过
不超过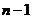 个,那么称为
个,那么称为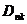 孤立点。如果对所有数据点根据其距离进行从大到小排序,那么前个点就被看作是孤立点。
孤立点。如果对所有数据点根据其距离进行从大到小排序,那么前个点就被看作是孤立点。
算法步骤如下,对每个点,计算它的第个最近邻居的距离,把具有极大值的前个点作为孤立点。该算法每次处理一个点,就需要扫描一遍数据库,总共需要扫描N遍(N为数据点数)。
结果与解释
输出结果:
孤立点表:列出孤立点的所在位置及详细信息。